Statistics Index
Testing Hypothesis
Introduction.....
Symbols.....
Hypothesis Test.....
Errors.....
Procedure.....
Tests Methods (Chi, T-test and F-tests).....
Examples.....
|
Introduction A hypothesis (Greek= assumption) is a proposed explanation for a
phenomenon. A supposition or assumption advanced as a basis for argument which is
tested using statistical methods generally using experimental samples.
1) The hypothesis be derive from a quality requirement *** Note: Statistical purist do not accept null hypothesis or alternative hypothesis. The notes below sufficient to enable a mechanical engineer to understand the principles involved, For more detailed information please use the linked sites or quality reference documents Symbols
Hypothesis Testing Generally the question of interest is simplified into two competing
claims ( hypotheses) the null hypothesis, denoted H0,
against the alternative hypothesis, denoted H1. These two hypotheses
are not however treated on an equal basis, special consideration is given to the
null hypothesis. Consider a typical population normal distribution with an assumed mean μ o.
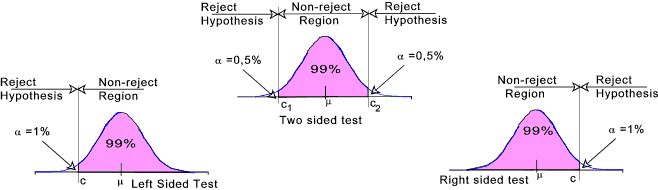
The alternative to the null hypothesis H0: μ = μ o can therefore take three forms μ > μ o The first two options are one sided and the third is a two sided alternative. Error Types In an hypothesis test two types of error can occur. A type I error and a
type II error. A type I error occurs when the null hypothesis is rejected when it is
in true; that is, H0 is wrongly rejected. A type II error occurs
when the null hypothesis H0, is not rejected when it is in fact false.
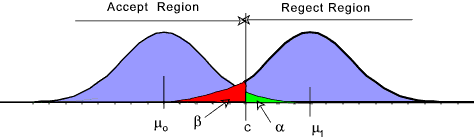
Consider the hypothesis that the mean of a population is μ o against an alternative hypothesis that the mean is a single value μ 1. This is clearly a simplified case of reality. μ 1 is greater than μ o and the problem is therefore a right handed test. The probability density curves of the variable under consideration showing the null hypothesis and the alternative hypothesis is shown below. The type I error with a probability (significance) of α is shown as is the type II error which has a probability (significance) of β. The figure below shows why it is better to use the term "not-reject" as opposed to "accept" e.g it is possible to have a high confidence (1- α ) that μ= μ o with a significant risk β that μ = μ 1 . Confidence = 1 - α The power of a statistical hypothesis test measures the test's ability to reject the null hypothesis when it is actually false. In other words, the power of a hypothesis test is the probability of not committing a type II error. It is calculated as 1- probability of a type II error. Clearly the higher the power the better. Power = 1 - P(type II error) = 1 - β It is generally not easy to calculate the significance β to enable the power to be determined as there may be infinite alternative hypothesis values. [It is very easy to calculate β if there was only one alternative hypothesis value e.g mean = μ1 ]. The primary method or reducing β and the consequent risk of a type II error is to increase the size of the sample (n). Increasing n reduces the sample standard deviation sx resulting in thinner bell shaped curves and moving c towards the centre of the accept hypothesis region
Procedure A typical procedure to be following in Hypothesis testing is shown below 1) Specify the null hypothesis Ho and the alternative hypothesis H1 F-test, T-tests, Chi-test A number of special statistical distributions are available for testing hypothesis and relevant notes are provided on the pages linked below....
1) F-tests Examples Example 1: It is assumed that the birth of a single child there is a 50% probability that
the child will be a girl and 50% will be a boy.
This hypothesis is tested by taking a sample of 4000 births in one year. The number of boys in
this sample is 2100. The sample seems to indicate that the hypothesis is wrong. n = the sample number, X = number of boys in 4000 births, p = the probability of boys. :Assuming that the hypothesis is true the critical value c is chosen from the equation. P ( X > c ) p= 0,5 = α = 0,01 Reference pages X has a binomial distribution with a mean = 0,5 .4000 = 2000 and a
variance σ 2 = n.p.(1-p)= 4000.0,5.0,5 = 1000. P (X > c) = 1 - P (X ≤ c) = (approx) 1 - Φ ((c-2000)/ √1000) = 0,01 From the normal distribution table - see ref page Φ(2,36) = 99%. Therefore 2,36 = (c - 2000)/ √1000. therefore c = 2074 The hypothesis to be tested is that the pupils in a particular school have above average IQ's. It is known that IQ scores are normally distributed with a mean μ = 100 and standard deviation σ = 15. A random sample of 11 children (n = 11) from the school shows a mean ( xm ) of 112.8. The standard deviation of the sample mean = σ /√(n)= 4,52 For this example the null hypothesis is that the pupils have an average - or below average IQ (μ ≤ μ o ). The alternative hypothesis
is that the pupils have an above average IQ μ > μ o The significance level μ is selected at 5% . The confidence level is therefore selected at 1 - 5% = The population is assumed to be normal The sample statistic xm = 112,8. This is greater than the critical value c and therefore the alternative hypothesis is not rejected The conclusion is that it is likely that the pupils in the school do have a higher than average IQ Example 3: Consider a sample (n= 18) from a population in a diet clinic as shown in the table below. The ideal weight is 100 and weights are expressed related to this ideal weight. The standard deviation of the population is not known. The hypothesis is that the weight of 100 is the population mean.
The sample mean is xm = 111,8 and the sample standard deviation sx = 14,24. The first requirement is to establish the null hypothesis: H0: μ = 100 The significance level α is set at 5% (This is the total area under the two tails) and therefore the confidence interval = (1- α) = -(this is the total area under the central "Accept Ho" region ) As the sample is a small sample and the population standard deviation is uknown the t-statistic is selected .
The number of degrees of freedom ν = n-1 = 17 The +ve t value relating to (1 - α ) = 0,5 + 0.95/2 = 0,975. is obtained by referring to the t-tables T-Tables t = = 2,11 In fact xm = 111,8 and this is outside the accept range and the hypothesis is therefore rejected. Notes to be added........................... |
Useful Related Links
|
|